
We wanted to know: Could AI tackle analysing a bilingual contract? We put three models—Claude, GPT-4, and ChatGPT 3.5 —to the test by challenging them to detect differences between English and Vietnamese versions of an agreement. The results revealed opportunities and limitations in using AI for this legal tech task.
Background.
In 2021 we engaged a software company in Vietnam to help deliver a software project.
Aside: They were absolutely great! Amazing developers and would highly recommend.
As part of our work we signed a contract which was in both English and Vietnamese

As part of thinking into legal-sector use cases for AI, I decided to see if AI could help parse the contract to highlight changes between the different language versions. And compare performance between different Large Language Models (LLMs). I had no idea if there were any differences, so this would be a journey of discovery!
The Prompts
The prompt was deliberately simple. I used basic language and let the LLM work it out.
I want you to compare a contract which is written in two languages and highlight any discrepancies. Do you understand?
The Contract
For ease, I pasted in three sections of the contract as text. I chose parts of the contract which had no identifiable information or specifics like day rates/deliverables.
The total length of the contract selected was ~2,750 words, which I would have expected to be ~3,600 tokens. But the Vietnamese characters seemed to affect OpenAI and made the token count much higher
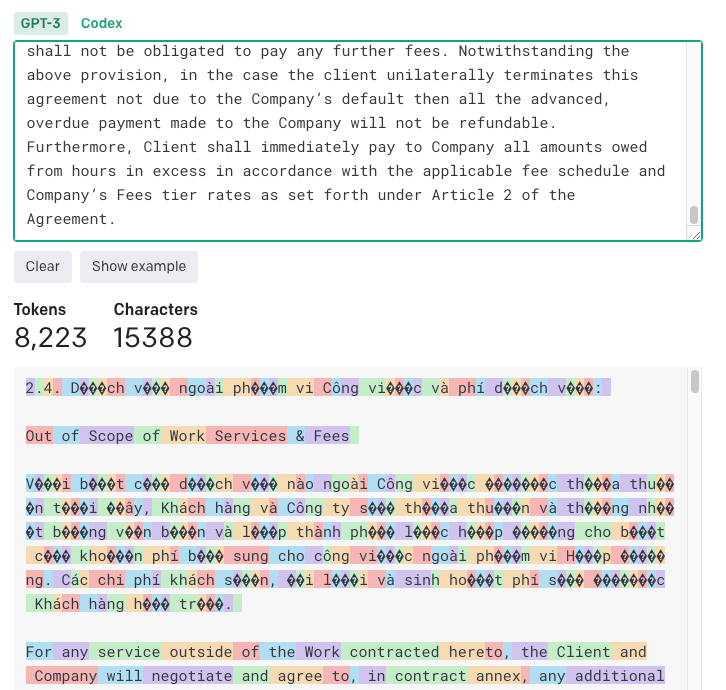
You can use OpenAI's Tokenizer to calculate the number of tokens.
The Battle!
Claude
Strong start from Claude, guiding me to try to fill in some of the gaps from such a broad prompt.
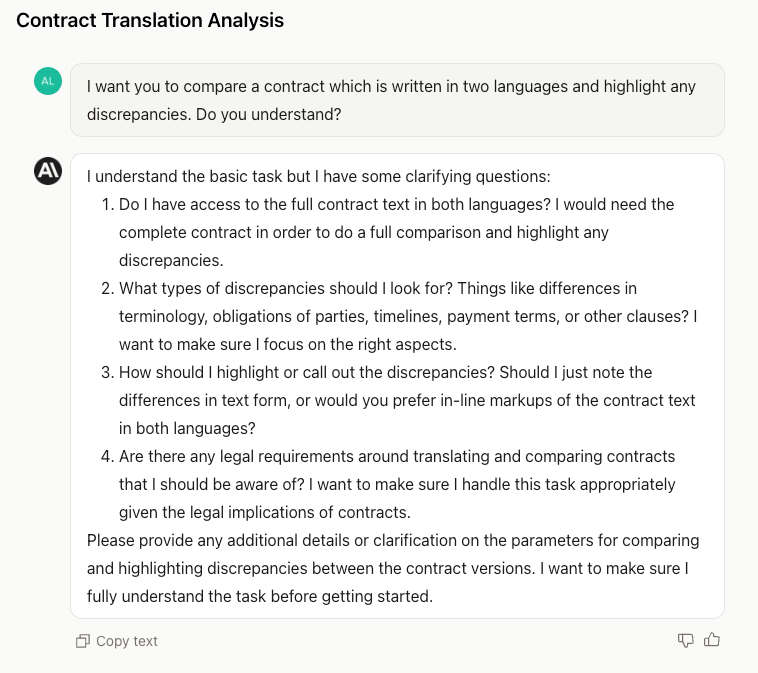
My response
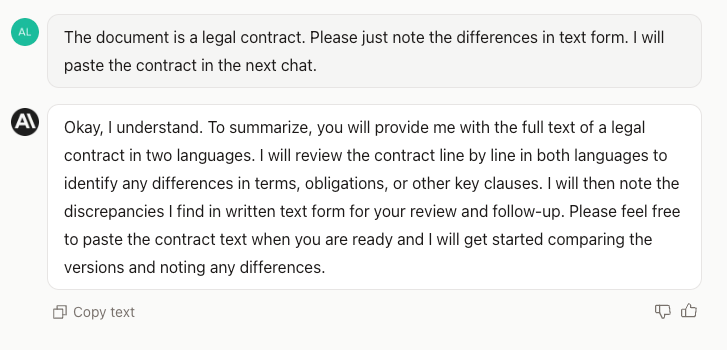
Text is pasted in, followed by a short instruction:

And the results!

Verdict

ChatGPT 3.5 Turbo
And we're off again:
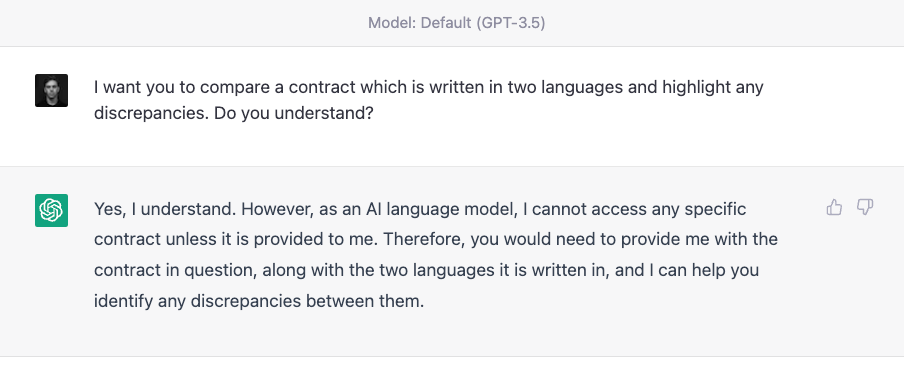
But... uh oh:
Ok so stumbled at the first attempt because of the tokenisation of Vietnamese language.
Lets split the doc roughly into two. Part one response:

Interesting - Claude didn't highlight any of these. They're all fairly minor in my opinion, but equally good to be aware of.
Now for the second part. (Spoiler, ChatGPT 3.5 seemed to get very lost very fast)
Response to part 2:

Try again:

And try again

It seemed happy the first time but now its not.
Verdict

GPT-4
Ok lets go for GPT-4. Instead of using ChatGPT, we'll use the API.
You'll notice I set the system prompt as a version of the original prompt to Claude. It could definitely be more verbose or specific, but I wanted to try to keep things consistent.
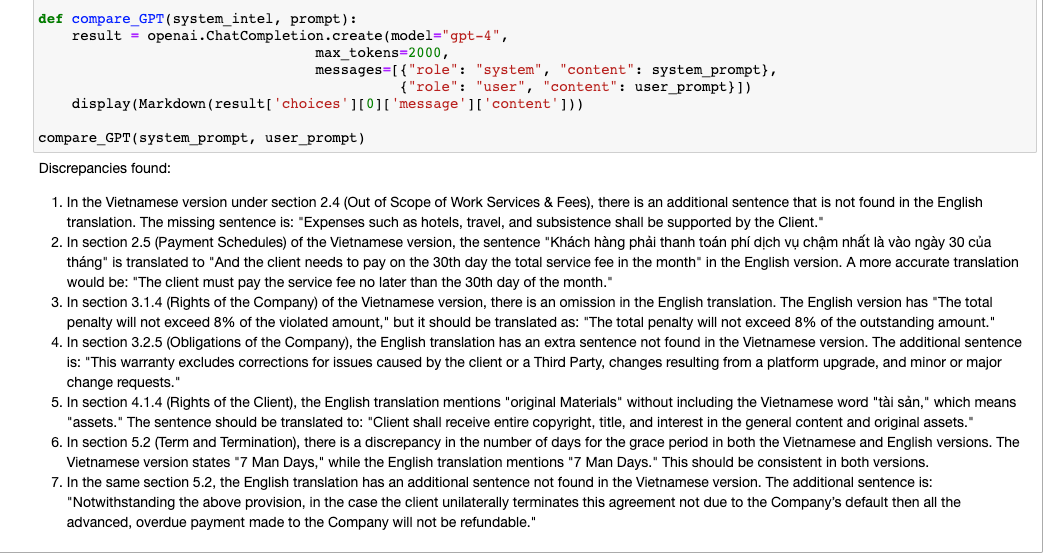
Ok seems promising. But on closer inspection finding 6 doesn't make sense. And finding 2 seems like its identified a difference, but its very minor.
Verdict

Learnings and improvements
If I had to name a winner it would be... Claude.🥇
This was a relatively quick and dirty test, and I think the real value add would be spending time optimising the prompt, ideally being specific about the types of errors. If as a lawyer you are able to build a better set of criteria, you could feed that to the model.
It's also unclear how good the models are at dealing with Vietnamese. This would be something to optimise for or invest time in understanding further.
The most telling thing is the lack of consistency across the different tools.
Definitely an opportunity for an international commercial law firm to build their own expertise out on top of it.