
Imagine you have a big book to read, but it's too hard to read the whole thing in one go.
So, you break down the book into smaller parts, like chapters, and read them one at a time. This way, it's easier to understand and remember what you read.
Language models like GPT-3 work in a similar way.
Instead of trying to understand all the words in a sentence at once, they break the sentence down into smaller parts called "tokens." These tokens are like little pieces of the sentence that the language model can read and understand more easily.
Using tokens makes it easier for the language model to read and understand a lot of text quickly, and it helps the model work with different languages and dialects. It also helps the model to be more accurate and understand things like the meaning of words better.
OpenAI's products like ChatGPT and Instruct GPT have transformed awareness of the possibilities of natural language processing. It has provided researchers, developers, and businesses with powerful tools to build various applications such as chatbots, content generators, and language translators.
However, the token limits in OpenAI present a challenge when generating long and structured outputs. To overcome this limitation, developers need to think creatively.
The token limit in OpenAI refers to the maximum number of characters or words that the model can process at once. From OpenAI
GPT family of models process text using tokens, which are common sequences of characters found in text. The models understand the statistical relationships between these tokens, and excel at producing the next token in a sequence of tokens.
In other words (no pun intended), when planning prompts or fine tuning, we have to think in terms of tokens, not words. Helpful guidelines (for English):
1 token ~= 4 chars in English
1 token ~= ¾ words
100 tokens ~= 75 words
You can see this in practice below

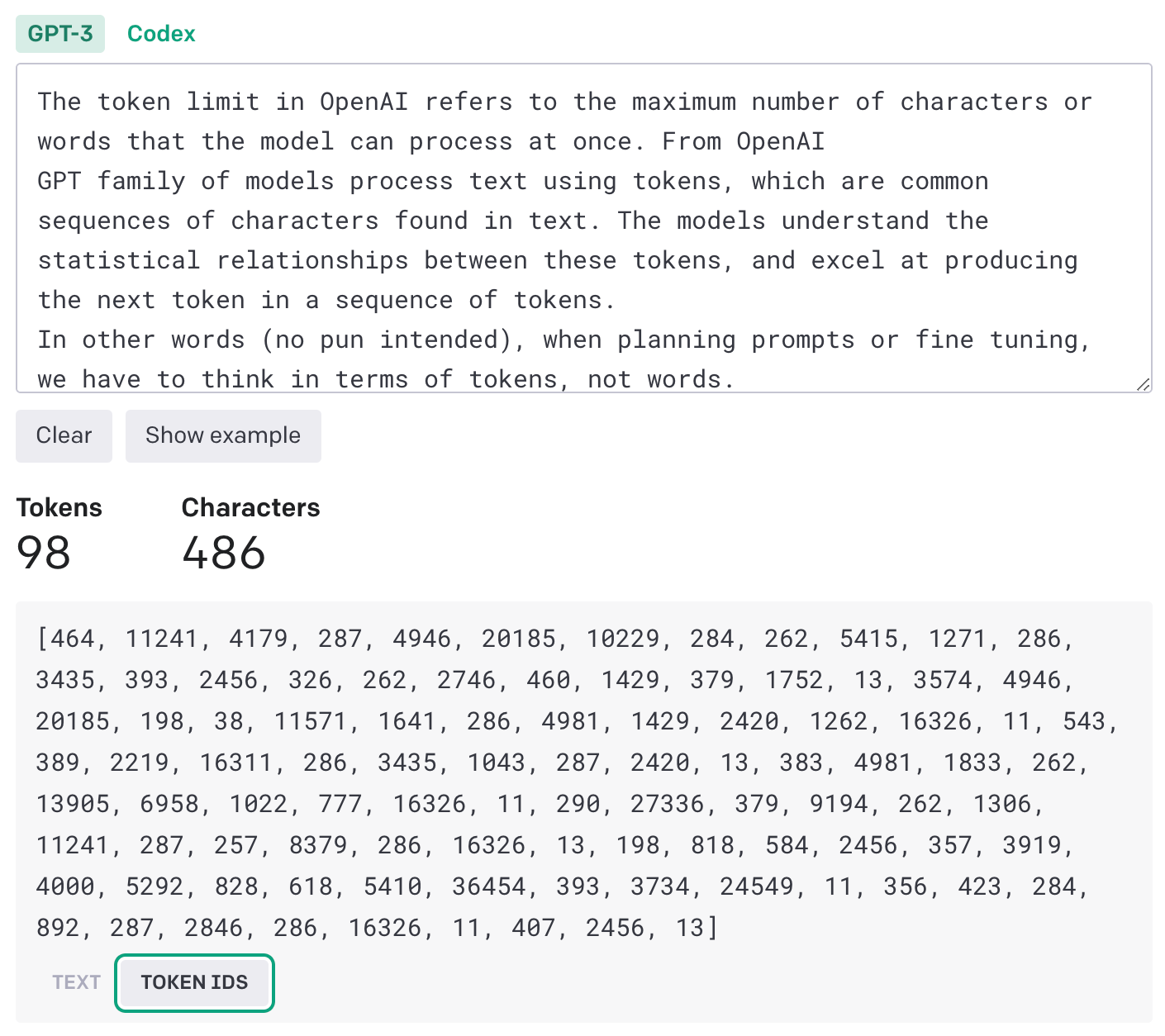
(The above screenshots are taken from the Tokenizer page of the OpenAI website.)
As at the time of writing Instruct models (like GPT-3) have a token limit of 4,097 for both prompt + completion, whilst fine tune datasets have a limit of 2,048.
This limit can cause issues when working with long documents or when generating complex outputs.
One way to address this challenge is to break down the input or output into smaller chunks or segments that can be processed separately. For example, when generating long articles or reports, one could divide the content into sections or paragraphs and generate each section separately. This approach not only helps to overcome the token limits but also allows for better organization and structure of the output.
Another strategy is to use summarisation techniques to condense long inputs into shorter, more concise outputs. Summarisation involves identifying the most important information in a text and presenting it in a condensed form. This approach can be particularly useful when working with long documents such as legal contracts, where summarizing the key terms and conditions can be more effective than presenting the entire document.
Furthermore, using templates and structured data can also be helpful in generating long, structured outputs. Templates provide a predefined structure for the output, making it easier to generate long outputs that follow a specific format. Structured data, such as tables or graphs, can also be used to present complex information in a more structured and concise manner.
To overcome the challenge of token limits when working with OpenAI's language models, it is necessary to devise creative solutions. These solutions may include breaking down inputs and outputs into smaller segments, using summarization techniques, and leveraging templates and structured data. By implementing these strategies, users can generate long, structured outputs while staying within the token limits, and create powerful and informative content with the help of OpenAI's advanced language models.